关于本文档
所有图表,示例,备注,以及明确标记为非规范的部分都是非规范的。其他内容都是规范的。
在本文档的规范部分中的关键字 "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", 和 "OPTIONAL" 在 RFC2119 的描述中有解释。为了方便阅读,这些词语不会以全部大写字母出现在本规范。
任何时刻,一个符合UA必须对状态或概念模型状态的反应做决定。这被称为算法。这些算法根据等价处理定义。等价处理 是强加给算法实现者的约束。对于相同的输入,要求UA实现和指定算法的输出必须保持完全一致。
依赖
本文档依赖以下规范:
术语
HTML导入, 或此后的 导入,是指在 HTML 文档 中作为 外部资源 链接 的 HTML 文档。 链接到一个 导入 的文档称为 导入来源。对任何给定的导入,一个 导入来源祖先 是它的 导入来源 或它的 导入来源 的任意 导入来源祖先。
一个有它自己的 浏览上下文 的 导入来源 被称为 主文档。 每个 导入 被关联到一个 主文档:如果 导入 的 来源 是一个 主文档,那么此 来源 是这个 导入 的 主文档。 否则,导入来源 的 主文档 是 导入 的 主文档。
一个 导入 的 URL 称为 导入地址。
在 导入来源 中,一个 导入 表示一个 Document, 称为 导入文档。导入文档 没有 浏览上下文。
主文档 关联的所有 导入 形成一个 主文档 的 导入映射。 此映射以 导入地址 作为键保存 导入。导入映射一开始是空的。新的项根据 导入获取算法 被添加到此映射中。
链接类型 "import"
为了能在HTML中声明 导入,HTML链接类型 增加了一个新的链接类型:
HTMLLinkElement 接口扩展
partial interface HTMLLinkElement {
readonly attribute Document? import;
};
import 属性 必需 返回 null,如果:
否则,此属性 必需 返回 导入 的 导入文档,由 link 元素呈现。
每次 必需 返回相同的对象。
在 HTML parser 或 XML Parser 的 Document 上下文中的 导入 被称为 阻塞脚本的导入。 如果此 元素 是 Document 的解析器创建的,或者这个 元素 是一个 import 类型的 link,而且此 link 没有被 标记为异步, 而且此导入已经 完全下载,且 事件循环 的最后时间已经到达步骤1,而且 元素 在 Document 中,而且用户代理尚未放弃此 导入。 用户代理可以随时放弃一个 导入。
如果在 文档 的 导入依赖 中存在 阻塞脚本的导入,那么此 文档 有可阻塞脚本的导入。否则此文档 没有阻塞脚本的导入。
Document 接口扩展
补充 document.open() 方法
增加如下步骤为定义的第一步:
补充 document.write() 方法
增加如下步骤为定义的第一步:
补充 document.close() 方法
增加如下步骤为定义的第一步:
加载 Imports
导入依赖
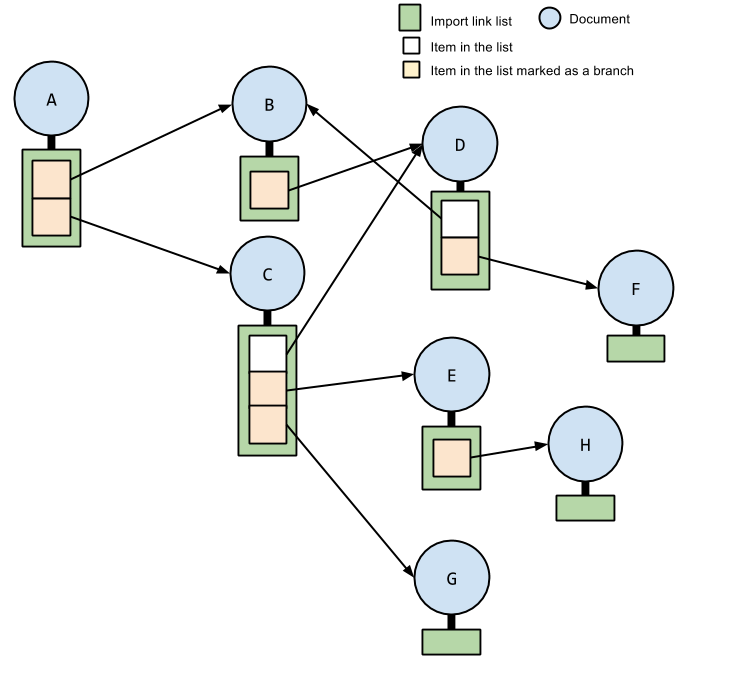
每个文档都有一个 导入链接表,其项都由 链接 构成, 包括 link 元素,URL地址。而且,项可以 标记为分支。此表开始为空,通过 导入请求 算法添加项。
一个 导入文档 有0个或多个 导入祖先。导入祖先 是一个文档。 如果文档 A 的 导入链接列表 包含一个 地址 指向文档 B 的 分支 项,那么 A 是 B 的一个 导入祖先。B 也称为 Document 的 导入父亲。导入祖先 是可传递的:如果文档 C 是文档 B 的一个 导入祖先,而文档 B 是文档 A 的一个 导入祖先,那么 C 是文档 A 的一个 导入祖先。
一个 导入文档 也有0个或多个 导入前置。 一个 导入前置 是一个文档。如果在文档 B 的 导入父亲 的 导入链接地址 里,文档 A 的URL地址位于文档 B 的URL地址之前,且定位 链接 被标记为 分支,那么 A 是 B 的 导入前置。
文档 A 的 导入祖先前置 定义如下:如果文档 B 是文档 C 的一个 导入前置,而 C 是文档 A 的一个 导入祖先,那么 B 是 A 的 一个 导入祖先前置。
如果一个 Document 是文档 A 的 导入祖先前置 或 导入前置,或者是链接到 A 的 导入链接表 的 分支 项,那么它是 A 的 导入依赖。
更新分支
在一个 链接 被添加到 导入链接表 后,更新标记 算法 必需 被 主文档 执行。等价于 执行如下步骤:
- 输入
- DOCUMENT,文档对象
- 如果 DOCUMENT 是 主文档,取消 DOCUMENT 的 导入链接表 中所有 链接 的 分支 标记, 所有 导入 都被关联到 DOCUMENT。
- 定义 LIST 等于 DOCUMENT 的 导入链接表。
- 对于 LIST 中的每个 ITEM:
- 定义 LOCATION 等于 ITEM 的 地址。
- 定义 IMPORT 为一个 URL 等于 LOCATION 的 导入。
- 如果没有其他的 链接 的 地址 与 LOCATION 相同且被标记为 分支,则标记 ITEM 为一个 分支。
- 如果 ITEM 被标记为 分支 且 IMPORT 不等于 null, 调用 IMPORT 的 更新标记 算法。
请求导入
当用户代理尝试 获取 一个链接导入, 它 必需 运行 导入请求 算法, 等价于 运行如下步骤:
- 输入
- LINK,建立到导入的 外部资源链接 的
link 元素。
- LOCATION,链接资源的 URL 。
- 如果 LINK 的 async 属性为 true, 则标记 LINK 为 异步。
- 定义 DOCUMENT 为 LINK 的一个文档。
- 定义 LIST 为 DOCUMENT 的 导入链接表。
- 定义 ITEM 为 LINK 和 LOCATION:
- 添加 ITEM 到 LIST 的末尾。
- 调用 主文档 的 更新标记 算法。
获取导入
所有链接到 主文档 或在 导入映射 中的 导入,必需使用如下描述的 导入获取算法,代替HTML规范指定的 获取链接资源 算法。
导入获取算法 必需 等价于 执行如下步骤:
当此算法完成,如果 IMPORT 不为null,则必需认为下载是成功的,否则为失败。
每个没有被 标记为异步 的导入会 延迟文档的加载事件。
导入和内容安全策略
内容安全策略 必需通过 script-src 指令限制导入的加载。
每个导入必需被 主文档 的内容安全策略限制。
例如,如果发送 内容安全头字段 到一个导入,用户代理必需 应用 主文档 的策略到导入文档。
解析导入
导入 的解析行为被定义为 HTML解析 的一组改变。
补充:准备一个脚本算法
在 准备一个脚本 算法的第15步,修改条件“如果元素没有 src 属性”的最后部分为:
补充:树构建算法
在 DOCTYPE 的章节部分 12.2.5.4.1 初始插入模式,修改 如果文档不是一个 iframe srcdoc 文档 ...
为如下:
如果文档不是一个 iframe srcdoc 文档,也不是一个 导入 ...
在 文本插入模式 的条件 Otherwise 的子条件“一个script结束标记”,修改步骤3为:
补充:解析XHTML文档
修改运行 准备 script 元素的第3步如下:
在导入中编写脚本
补充:脚本启用标准
增加下述条件到 开启和关闭脚本 标准列表:
补充:document.currentScript
修改 document.currentScript 的定义为:
currentScript 属性,必需返回文档或文档的
导入映射 中最近初始化的脚本。当文档创建后,
currentScript 属性必需初始化为 null。如果文档为
导入文档,那么它的
currentScript 始终为 null。
导入的样式处理
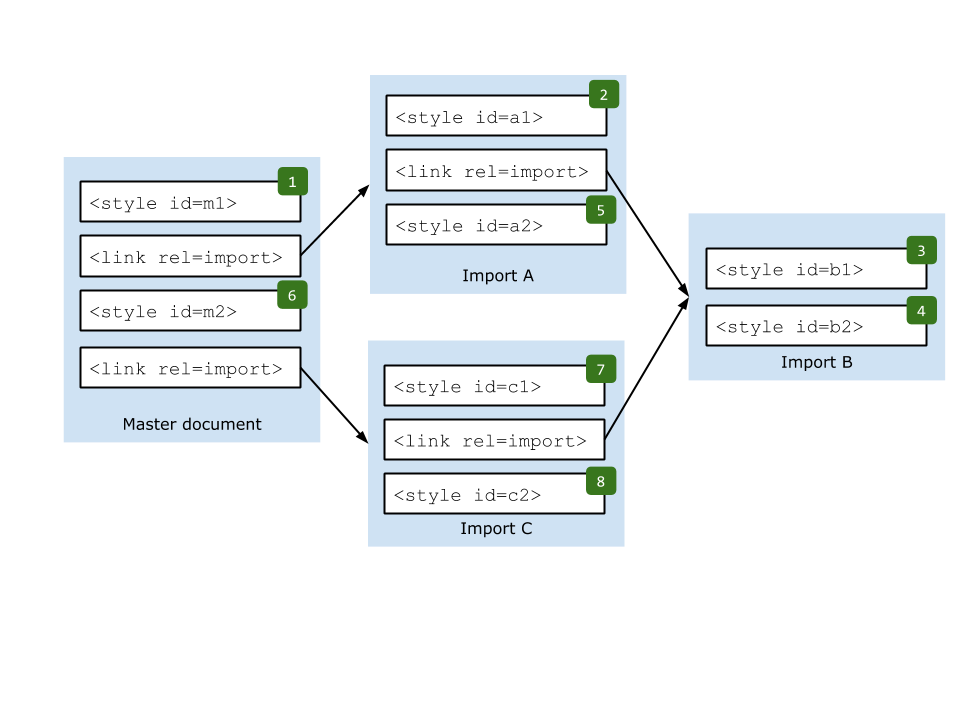
导入 的 style 元素和外部资源 link 元素的内容必需被当做 主文档 的 样式处理模型 的输入源。
不同文档之间的文档顺序中的 出现顺序 被定义为,比较两个元素,x,其所在文档是 Dx,和 y,其所在文档是 Dy,如下:
- 如果有一个文档 Da,它是 Dx 和 Dy 的公共 导入来源祖先,Lx 是 Da 中第一个链接到 Dx 或 Dx 的 导入来源祖先 的导入
link 元素,Ly 是一个单独导入 Dy 的 link 元素。使用文档顺序比较两者,如果 Lx 在前,则元素 x 在前,否则 y 在前。
- 如果 Dx 是 Dy 的一个 导入来源祖先,Ly 是 Dx 中第一个链接到 Dy 或 Dy 的 导入来源祖先 的导入
link 元素。比较 x 的文档顺序和 Ly,如果 x 在 Ly 前面,那么 x 也在 y 的前面。
- 如果 Dy 是 Dx 的一个 导入来源祖先,则比较 y 的文档顺序和 Lx。
参见 Bug 24756.
导入中的事件
导入 中的事件被定义为一组 HTML事件 改变。
附加:事件处理器
修改 事件处理器内容属性 的脚本创建标准,扩展第一段:
鸣谢
David Hyatt 开发了 XBL 1.0,Ian Hickson 参与了 XBL 2.0 的编写。这些文献在行为依附问题上提供了巨大而深刻的见解,并极大地影响了本说明书。
Alex Russell 和他的重要远见引发了新一波围绕行为依附课题的热潮和如何在网络上应用于实践。
Dominic Cooney 和 Roland Steiner 不知疲倦的仔细研究网络平台范围内的问题,为此文档打下了坚实的基础。
编辑还要感谢 Alex Komoroske,Angelina Fabbro,Anne van Kesteren,Boris Zbarsky,Brian Kardell,Daniel Buchner,Edward O'Connor,Eric Bidelman,Erik Arvidsson,Elliott Sprehn,Gabor Krizsanits,Hayato Ito,James Simonsen,Jonas Sicking,Ken Shirriff,Neel Goyal,Olli Pettay,Rafael Weinstein,Scott Miles,Steve Orvell,Tab Atkins,William Chan,和 William Chen,感谢他们对此说明书的评论和贡献。
这个列表太短了。还有很多工作要做。请通过评审和提交bugs来参与贡献 — 不要忘了要求编辑添加你的名字到此章节。